保真的读写方式
这是什么意思呢?先看两个代码示例:
示例一
来自 sjPlot 的示例,青椒群主丁哥也提到了(青椒),不过遇到障碍就略过,不符合我们 rebuild the wheel 的风格。中文是我的第二母语,我不跟中文较劲谁来较劲。
library(sjPlot)
library(sjmisc)
data(efc)
# 我要跟中文较劲之1
attr(efc$c160age, 'label') <- '年龄'
fit1 <- lm(barthtot ~ c160age + c12hour + c161sex + c172code, data = efc)
sjt.lm(fit1)
# 我要跟中文较劲之2
attr(efc$c160age, 'label') <- iconv('年龄', to = 'UTF-8')
fit1 <- lm(barthtot ~ c160age + c12hour + c161sex + c172code, data = efc)
sjt.lm(fit1)
显示的表格是这样的:
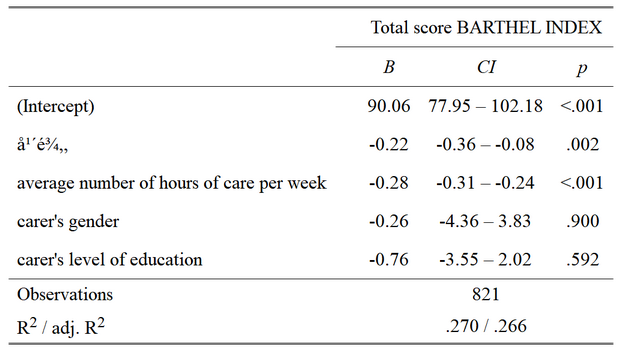
统统可耻地失败了!!!夜深人静之时,熬到双眼通红,改代码改到崩溃也没有解决,对不对?
示例二
示例二需要一些工具准备工作。博主用的是 UltraEdit 这款文本处理专业助手。顺便说一句,做数据处理的人,必须得心应手的运用一款这样的专业工具,否则就是毛笔刷水桶,筷子搅大缸,根本就是数据处理的门外汉。
不同编码的真实面目
这里用 UltraEdit 来干什么呢?查看文本的字符编码。编码的原理不再重复介绍了,网上资源大把。就看几个典型的文本编码是什么样子:
图1:这是人畜无害的记事本显示的文本

图2:十六进制下 GB 码的样子

图3:十六进制下 UTF-8 没有 BOM 的样子

图4:十六进制下 UTF-8 有 BOM 的样子,多了 EFBBBF 的标记

其它的编码比如 UTF-16 这些就不再一一展示了。我们就是要用 UltraEdit 来帮助R检查输入输出有没有问题,确保 UltraEdit 看到的编码和 R 读写的一致。目标很简单,保真,也就是要求 R 读进来的文本编码与原始的一致,R 写出来的文本编码与 R 内存中的一致。对于有一点编程经验的人来说,这个要求似乎一点都不高。对于随机数都是“伪”的软件编程来说,消除不确定性不是天经地义的嘛?
示例二
事实真是如此嘛?让我们检验一下。
options('encoding')
## $encoding
## [1] "native.enc"
(x1 <- readLines('datacarpenter_ansi.txt'))
## [1] "数据匠"
(x2 <- readLines('datacarpenter_utf8.txt', encoding= 'UTF-8'))
## [1] "数据匠"
(x3 <- readLines('datacarpenter_utf8bom.txt', encoding = 'UTF-8'))
## [1] "数据匠"
Encoding(x1)
## [1] "unknown"
Encoding(x2)
## [1] "UTF-8"
Encoding(x3)
## [1] "UTF-8"
目前为止还都符合预期。那么在 UTF-8 系统下是什么样子呢?
Sys.setlocale('LC_CTYPE', locale = "English_United States.1252")
## [1] "English_United States.1252"
options(encoding='UTF-8')
(x1 <- readLines('datacarpenter_ansi.txt', encoding = 'unknown'))
## [1] ""
## Warning messages:
## 1: In readLines("datacarpenter_ansi.txt", encoding = "unknown") :
## invalid input found on input connection 'datacarpenter_ansi.txt'
## 2: In readLines("datacarpenter_ansi.txt", encoding = "unknown") :
## line 1 appears to contain an embedded nul
(x2 <- readLines('datacarpenter_utf8.txt', encoding= 'UTF-8'))
## [1] "?"
## Warning messages:
## 1: In readLines("datacarpenter_utf8.txt", encoding = "UTF-8") :
## invalid input found on input connection 'datacarpenter_utf8.txt'
## 2: In readLines("datacarpenter_utf8.txt", encoding = "UTF-8") :
## incomplete final line found on 'datacarpenter_utf8.txt'
Encoding(x1)
## [1] "unknown"
Encoding(x2)
## [1] "unknown"
惨不忍睹啊!还有一点,再次告诉我们,Windows 本身就是支持Unicode的系统,只要系统的语言和区域设置正确(在控制面板中),就用不着设为统一的 UTF-8 体系,否则就是摁下一个小葫芦起个超级大瓢。
那么写入呢:
x1 <- '数据匠'
writeLines(x1, 'chn_ansi.txt')
x2 <- iconv(x1, to = 'UTF-8')
writeLines(x2, 'chn_utf8.txt')
看上去还不错,无论是 GB 码还是 UTF-8 码都显示正确。
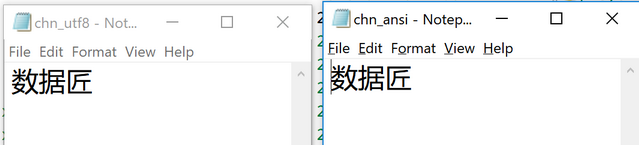
除了一点,为何这两个文件的大小是一模一样的的呢?用 UltraEdit 查看它们的十六进制内容,也是一模一样的,有没有!
喜欢读帮助文档的读者就会提醒了,加上 useByte 参数可破!确实,useByte = TRUE 参数可确保写入 UTF-8 文本,不过有个前提,就是当编码与 options('encoding') 不一致的时候。如果碰到改了 options() 参数的时候,就不一样了:
options('encoding' = 'UTF-8')
x = iconv('中华人民共和国', to = 'UTF-8')
# 写入乱码
writeLines(x, con = 'test.txt', useBytes = T)
## Warning message:
## In writeLines(x, con = "test.txt", useBytes = T) :
## invalid char string in output conversion
readLines("test.txt", encoding="UTF-8")
## [1] "中华人民共和\xe5\u009b"
在上面这个例子中,文本是 UTF-8 编码,options() 设置是 UTF-8 编码,写入是字节码,一切可能的设置都已经做到perfect,完美统一,可是忒么的写到磁盘就是乱码!如果你是个较真的人,是不是会觉得很别扭,很糟心?
所以,尽管针对每个特定的情形,都能找到相应的解决方案,但是这些方案都取决于特定的系统设置。因此,同样的代码在不同人的设备不同的环境下面跑,出错就在所难免了。并且,像上面这样的代码书写起来不是非常的单调、重复、丑陋无比嘛?
那么不用 readLines() writeLines() 这些函数就好了嘛,还有更高效的 data.table 的 fread(),readr 的各种 read_*** 函数可用。是这样,仅仅只是数据导入还好办,不过大量的输出相关 R 包,比如示例一中的 sjplot、stargazer,幻灯输出的 slidify,动态网页和D3.js 输出的 clickme等等,大量的包都依赖于 readLines()、writeLines()以及cat() 这些基础函数。用 R 就是要享受这种全流程工作链的感觉。想象一下,把你的博士论文全程用 R 计算并生成,这真的不是幻想。
本系列博文的目标就是要找到一种可靠的不受各种外部系统设置影响的方式来实现保真的编码读写,同时,要有足够的兼容性,通过一点简单的操作就能一举消除大量的第三方包所存在的乱码 bug,无需一个个去提醒各个包的开发者去做修改。你能体会跟老外去沟通,让他们去理解这些乱码问题是多么费劲的一件事情嘛?更何况下个版本升级不小心又改回去了呢?以上都是博主遭遇过的血泪史。
这个泡泡是不是吹的有点大了?